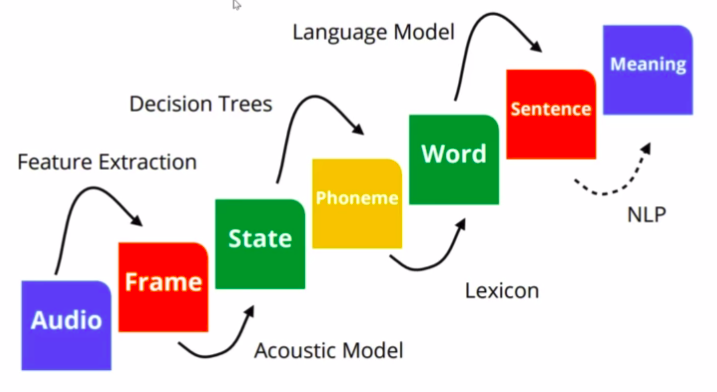
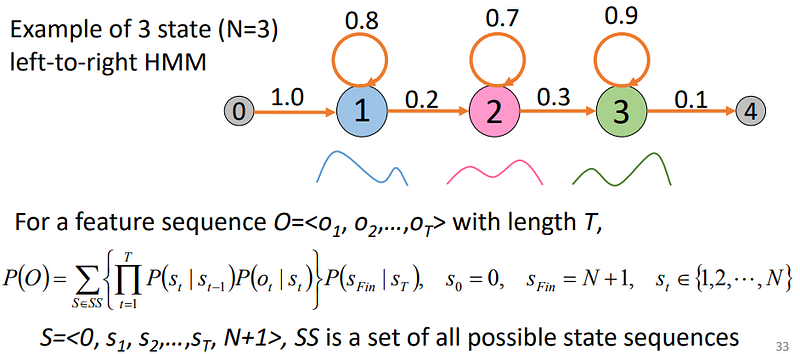
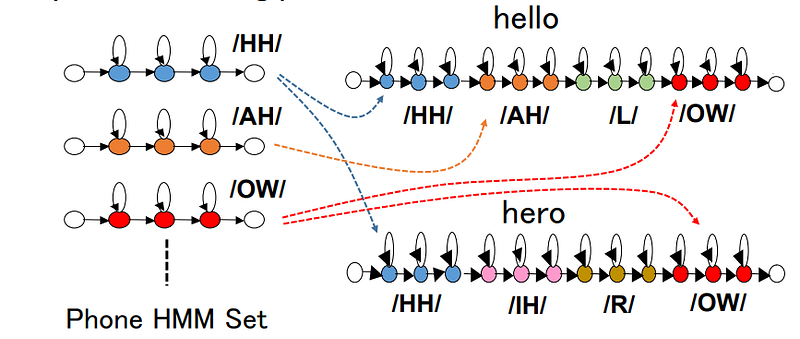
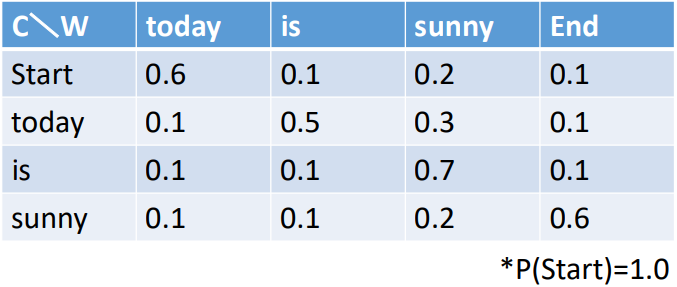
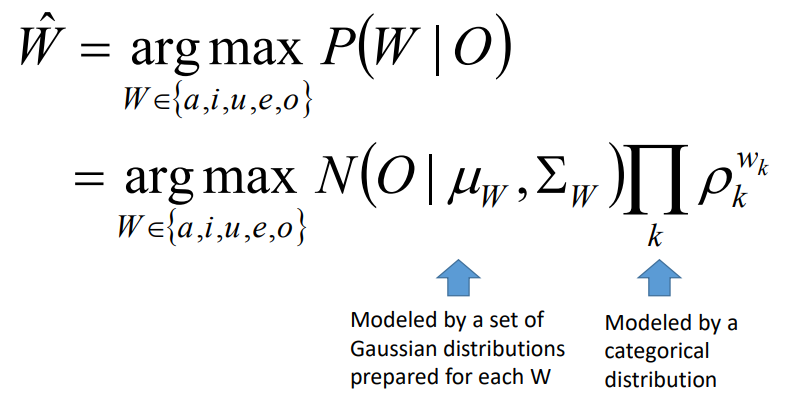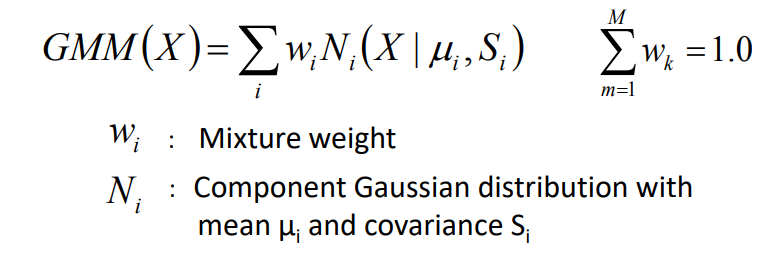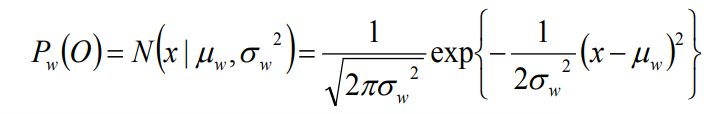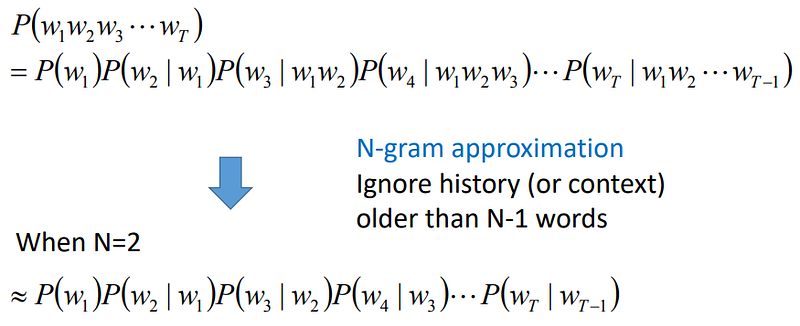Learning Speech Recognition (part 3)
Pada Part 3 ini akan dibahas tentang tahap selanjutnya di speech recognition. Komponen yang akan dibahas pada artikel ini adalah Phonem, pembuatan lexicon (WSFT), dan akhirnya menjadi kata.
Fonem
Ketika berbicara tentang fonem, terdapat komponen-komponen kebahasaan lainnya dalam sebuah ucapan. Dalam kamus KBBI v5 kata fonem memiliki arti sebagai berikut: Fonem adalah satuan bunyi terkecil yang mampu menunjukkan kontras makna (misalnya / h/ adalah fonem karena membedakan makna kata harus dan arus, /b/ dan /p/ adalah dua fonem yang berbeda karena bara dan para beda makna).

Fonem merupakan satuan terkecil dari bunyi yang menyusun komponen yang lain. Terdapat Silabel — Morfem — kata — frasa — kausa — kalimat — paragraf — wacana pada sebuah komponen kebahasaan. Dalam bahasa Indonesia masih terdapat beberapa pebedaan tentang jumlah keseluruhan fonem. Ada yang menyebut 33 fonem, 37 fonem, maupun hingga 42 fonem. Berikut daftar fonem yang ada dibahasa indonesia
penjelasan lebih lanjut mengenai fonem ini bisa dilihat di artikel ini dan link github berikut.
Lexicon
Setelah mengetahui tentang fonem, yang merupakan komponen terkecil dari satuan bunyi. Lalu, bagaimana caranya mengumpulkan fonem-fonem menjadi kata yang agar lebih mudah untuk dibaca dan diketahui artinya kemudian? Sebelum itu, ada baiknya diketahui bentuk dari lexicon itu. Contohnya (link) :
dia : d i a
aku : a k u
rasa : r a s a
dengan : d e ng a n
punya : p u ny a
dsb
jadi lexicon itu merupakan kumpulan fonem yang membentuk kata atau dalam kata lain, cara baca dari setiap kata. Dalam bahasa indonesia terdapat sekitar 60000 hingga 80000 kata yang tercatat dalam KBBI V5 (selain kata gabungan, frasa), belum lagi ditambah dengan kata-kata tidak baku.
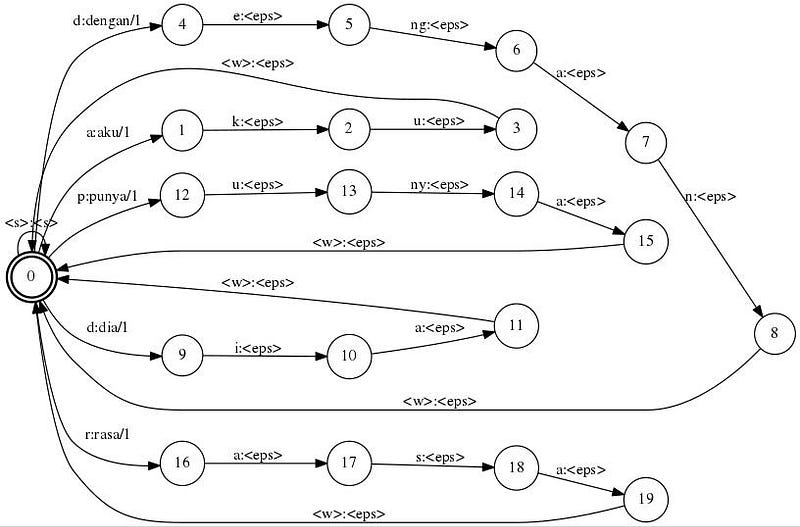
Seluruh kata tersebut kemudian dibuat menjadi graph dengan setiap node nya merupakan fonem dari kata itu. Berikut gambar yang akan menjelaskan graph yang dimaksud.

$ fstcompile --isymbols=ascii.syms --osymbols=wotw.syms >graf_kata.fst <<EOF
> 0 1 a aku > 1 2 k <epsilon> > 2 3 u <epsilon> > 0 4 d dengan > 4 5 e <epsilon> > 5 6 ng <epsilon> > 6 7 a <epsilon> > 7 3 n <epsilon> > 0 8 p punya > 8 9 u <epsilon> > 9 10 ny <epsilon> > 10 3 a <epsilon> > 3 > EOF
lalu generate gambar jpg:
$ fstdraw --isymbols=ascii.syms --osymbols=wotw.syms -portrait graf_kata.fst | dot -Tjpg >graf_kata.jpg
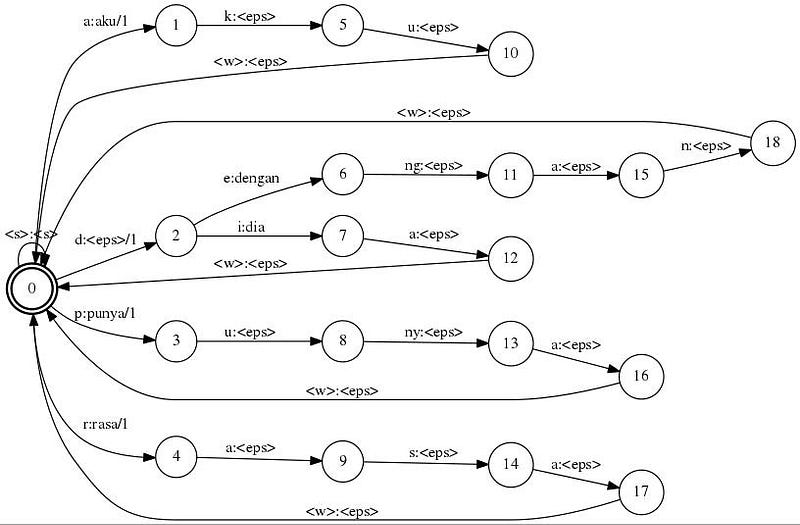
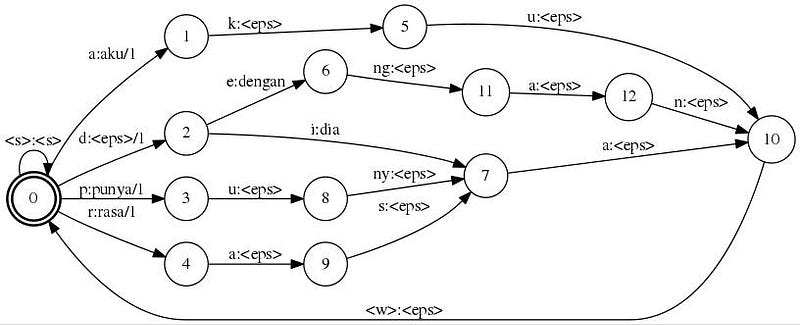
Cara lain untuk membuat model graf agar lebih mudah dapat mengikuti tutorial berikut ini (link). Berikut tahap-tahapannya agar dihasilkan graf yang lebih efisien. kita dapat menggunakan fstdeterminize, fstminimize, dan fstarcsort dari tools openfst.
- preparing data dari corpus yang ada. Buat daftar phonem dan daftar kata.
- generate plain data untuk pembuatan graf fst
- generate graf tahap 1 (buat graf untuk masing-masing kata)
4. generate graf tahap 2 (optimasi kata yang beririsan)
5. generate graf tahap 3 (optimasi kata yang beririsan)
Calculate WSFT
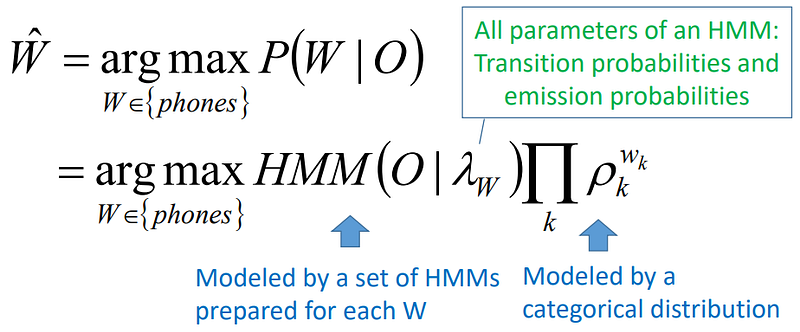
Untuk melakukan penggabungan Graf, optimasi, dan melakukan operasi-operasi lainnya seperti contoh diatas, terdapat beberapa Algoritma pada WFST ini. Mulai dari Composition, Epsilon-removal, Determinization, Weight-pushing, hingga Minimization (link). Sebelumnya akan dibahas dahulu tentang pembobotan yang ada di WSFT dikenal dengan nama lain Semirings, beberapa variasi dari weight pada FST akan dijelaskan dari tabel berikut (link):
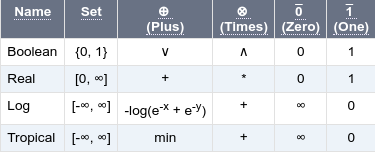
- Jenis pembobotan tipe Boolean digunakan untuk automata tanpa bobot yang familiar (lihat tropical).
- Jenis pembobotan tipe Real disesuaikan ketika transisi bobot mewakili probabilitas.
- Jenis pembobotan tipe Log disesuaikan ketika transisi bobot mewakili negatif log probabilitas.
- Jenis pembobotan tipe Tropical disesuaikan untuk operasi shortest path dan identik untuk log kecuali menggunakan operasi min dan plus.
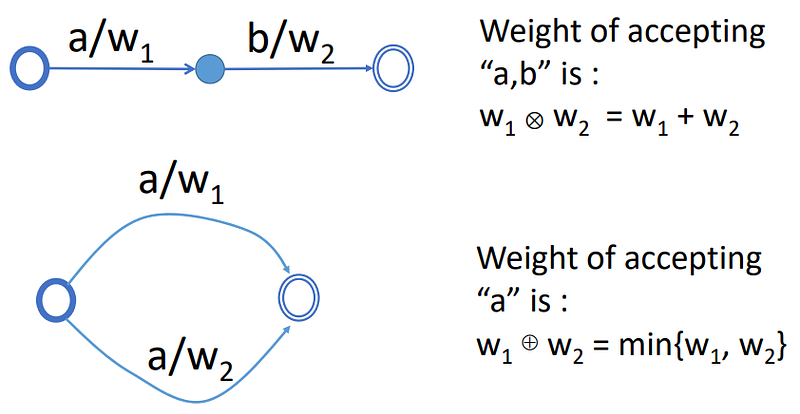
satu hal lagi yang harus dibahas sebelum pebahasan algoritma dari WSFT adalah mengetahui perbedaan antara Transducer dan Acceptors (link page6).
“Definisi A WFST is defined as an 8-tuple, T = (Σ, !, Q, I, F, E, λ, ρ). Here Σ represents the finite alphabet of input symbols, ! represents the finite output alphabet, Q represents the finite set of states, I ⊆ Q the set of initial states, F ⊆ Q the set of final states, E ⊆ Q × (Σ ∪ {#}) × (! ∪ {#}) × K × Q a finite set of state-to-state transitions, λ : I → K the initial weight function, and ρ : F → K the final weight function mapping F to K .”
- WSFA hanyalah sebuah WSFT, hanyasaja label output yang dihilangkan.
- Demikian pula FSA dan FST yang hanya tidak memiliki bobot.
Selanjutnya akan dibahas beberapa algoritma yang penting pada WSFT, dapat kita gambarkan seperti diagram dibawah ini.
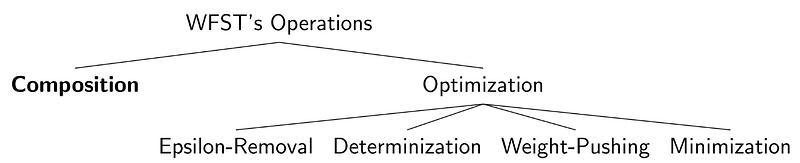
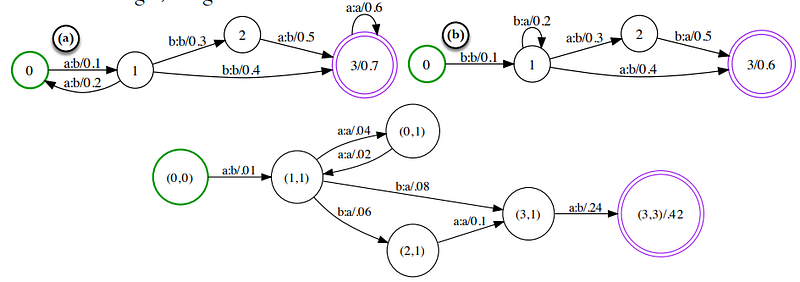
- Composition : operasi ini digunakan untuk melakukan kombinasi antar dua transduser yang terkait.Cara kerja dari operasi ini dapat dilihat di link berikut (link1). Sedangkan contoh soal penyelesaian dengan operasi composition ini dapat dilihat juga di link video berikut (link2).
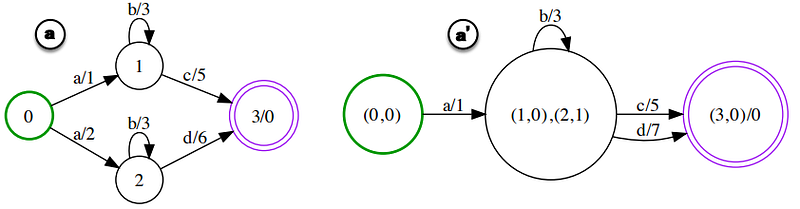
2. Determinization : operasi yang digunakan unutk menghilangkan ambiguitas dari path input. Tujuannya berguna untuk meningkatkan efisiensi dan tuga meningkatkan kecepatan runtime.
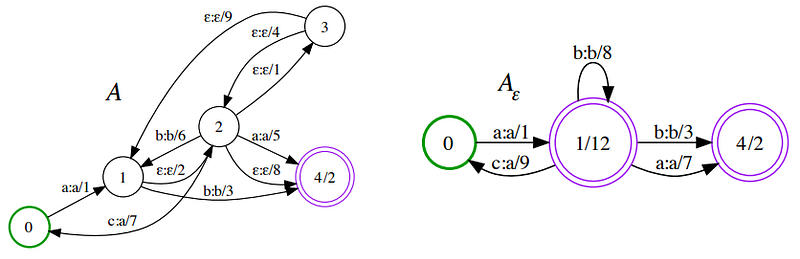
3. Epsilon-Removal : operasi ini digunakan untuk menghilangkan epsilon atau input kosong. Tujuannya untuk memperkecil delay pada operasi yang sedang berlangsung.
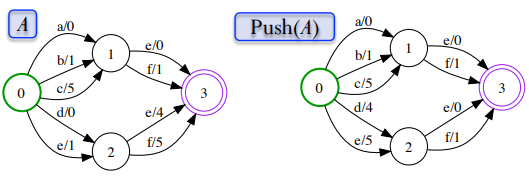
4. Weight-Pushing : memindahkan (pushing) bobot kebagian depan atau belakang, dapat berupa enumpukkan atau mendistribusikan kemana saja unutk proses semiring.
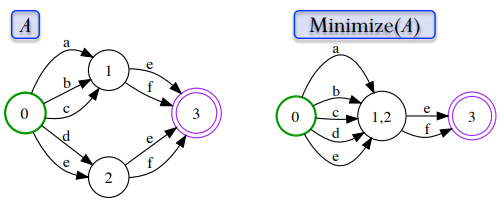
5. Minimization : operasi yang digunakan unutk memperkecil jumlah states untuk menghasilkan versi yang minimal, dengan tetap mempertahankan nilai dari input language dan path / weight.
Sekian untuk part 3 ini, semoga untuk part 4 dan selanjutnya akan disegerakan penyelesaian penulisannnya. Mohon dukungannya ya…
Insyaallah part selanjutnya akan di bahas tentang Maximum likelihood estimation, Bayesian, inference sampling, penggunaan DNN dalam speech recognition dsb. :)
referensi:
- https://white.ucc.asn.au/Kaldi-Notes/fst-example/
- http://semangatkecil.blogspot.com/2018/09/menelisik-komponen-kebahasaan-untuk.html
- https://github.com/kirralabs/indonesian-fonem
- http://www.openfst.org/twiki/bin/view/FST/FstExamples
- https://cs.nyu.edu/~mohri/pub/hbka.pdf
- http://www.gavo.t.u-tokyo.ac.jp/~novakj/wfst-algorithms.pdf
- http://www.phontron.com/kyfd/tut1/
- http://kaldi-asr.org/doc/graph_recipe_test.html
- http://www.lvcsr.com/static/pubs/apsipa_09_tutorial_dixon_furui.pdf
- https://www.youtube.com/watch?v=DyY69sX7RGk&t=1s
- HCLG https://www.inf.ed.ac.uk/teaching/courses/asr/2016-17/asr11-wfst.pdf
- google https://ai.google/research/pubs/pub45528
- https://cmusphinx.github.io/2012/06/using-opengrm-ngram-library-for-the-encoding-of-joint-multigram-language-models-as-wfst/
- https://medium.com/explorations-in-language-and-learning/an-introduction-to-speech-recognition-using-wfsts-288b6aeecebe
- (phonem to word >>> 43:42) https://www.youtube.com/watch?v=HyUtT_z-cms&t=1514s