
Learning Speech Recognition (Intro)
Mungkin di saat sekarang, teknologi speech recognition (pengubah suara ke text) sudah tidak asing lagi bagi kaum milenial. Speech recognition atau pengenal wicara memungkinkan sebuah sistem yang dapat mengenali dan menterjemahkan apa yang dikatakan oleh manusia ke dalam bentuk text.
Pengenalan ucapan atau pengenalan wicara — dalam istilah bahasa Inggrisnya, automatic speech recognition (ASR) — adalah suatu pengembangan teknik dan sistem yang memungkinkan komputer untuk menerima masukan berupa kata yang diucapkan. Teknologi ini memungkinkan suatu perangkat untuk mengenali dan memahami kata-kata yang diucapkan dengan cara digitalisasi kata dan mencocokkan sinyal digital tersebut dengan suatu pola tertentu yang tersimpan dalam suatu perangkat. Kata-kata yang diucapkan diubah bentuknya menjadi sinyal digital dengan cara mengubah gelombang suara menjadi sekumpulan angka yang kemudian disesuaikan dengan kode-kode tertentu untuk mengidentifikasikan kata-kata tersebut. -Wikipedia-

Beberapa tipe Speech Recognition (berdasarkan utterance-nya)
Terdapat beberapa tipe sistem dalam speech recognition yang digunakan sekarang ini. Sistem ini dibedakan berdasarkan kemampuan sistem untuk menterjemahkan sebuah utterance.
- Isolated Word: sistem ini membutuhkan jeda pada setiap awal dan akhir utterance. Sistem ini dapat melakukan proses pengolahan lebih dari satu kata, hanya saja membutuhkan selang jeda untuk memproses suara sebelumnya.
- Connected Words: sistem ini hampir sama dengan isolated word hanya saja memungkinkan utterance yang terpisah untuk berjalan bersamaan dengan batasan yang kecil pada antar uterance-nya.
- Continuous Speech: sistem ini memungkinkan seseorang untuk berbicara kesistem hampir secara natural, ketika komputer menterjemahkannya.
- Spontaneous Speech: sistem ini memugkinkan untuk menterjemahkan ucapan seseorang secara natural. sistem ini mampu untuk menangani berbagai fitur ucapan senatural mugkin, seperti kata-kata yang dijalankan bersamaan.
Beberapa tipe Speech Recognition (berdasarkan model pembicaranya)
Setiap orang memiliki suara yang unik. Ketika berbicara seseorang dapat membedakan suara orang lainnya dengan mudahnya. Berbeda dengan sebuah sistem, komputer tidak mudah menterjemahkan suara dari setiap orang. Sebab dari itu speech recognition dibedakan berasarkan model pembicaranya.
- Speaker Dependent Models: sistem ini dapat melakukan penterjemahan suara menjadi teks pada orang tertentu, tetapi agak sulit untuk menterjemahkan pada suara orang yang lainnya. Keuntungan sistem ini dapat dikembangkan secara mudah dan lebih akurat.
- Speaker Independent Models: sistem ini memiliki kemampuan untuk menterjemahkan suara lebih general, lebih banyak orang yang dapat menggunakan sistem ini dalam sekali pengembangan. Sistem seperti ini merupakan sistem yang lebih sulit untuk dikembangkan dan lebih tidak akurat dari Speaker Dependent Models.
- Speaker Adaptive Models: sistem ini dikembangkan menggunakan sistem Speaker Dependent Models, tetapi dilakukan adaptasi untuk dapat menterjemahkan suara orang yang lain dari sistem yang telah dibuat sebelumnya.
Beberapa tipe Speech Recognition (berdasarkan banyak katanya)
semakin akurat sebuah sistem yang dikembangkan berdampak pada nyamannya pengguna untuk menggunakan sebuah sistem. Artinya semakin nyaman sebuah sistem dapat ditentukan pada banyaknya kata-kata yang dapat diterjemahkan, yang pastinya semakin kompleks sistem yang harus dikembangkan. Hal lainnya yang dapat dilakukan adalah dengan menentukan target yang lebih spesifk untuk mengembangkan sistem yang lebih sederhana. berdasarkan besaran katanya, speech recognition dibedakan menjadi beberapa bagian.
- Small Vocabulary: banyaknya sekitar 1 sampai 100 kata atau kalimat
- Medium Vocabulary: banyaknya sekitar 101 sampai 1000 kata atau kalimat
- Large Vocabulary: banyaknya sekitar 1001 sampai 10,000 kata atau kalimat
- Very-large vocabulary: banyaknya lebih dari 10,000 kata atau kalimat
Perkembangan Speech Technology
Speech recognition mengalami perkembangan yang cukup signifikan selama beberapa tahun belakangan ini, semenjak kemampuan komputasi meningkat sistem ini pun semakin baik. Meskipun pengambangan sistem ini sudah dilakukan semenjak puluhan tahun yang lalu. Tipe-tipe sistem pada speech recognition yang sudah dibahas diatas menunjukan tahapan perkembangan pada teknologi ini. Berikut sejarah perkembangan teknologi speech recognition.
- 1784 : (3) Wofgang von Kempelen creates the Acoustic-Mechanical speech Machine in Vienna
- 1791 : (1) Kempelen’s talking machine
- 1857 : (1) Phonautograph
- 1876 : (1) Telephone
- 1879 : (3) Thomas Edison invents the first dictation machine
- 1900 : (1) Radio broadcast
- 1920 : (1) Radio Rex
- 1939 : (1) Vocoder
- 1946 : (1) ENIAC
- 1952 : (1) Digit recognition (3) Bell Labs releases Audrey, capable of recognizing spoken digits with 90% accuracy — but only when spoken by its inventors
- 1960s : (2) Dynamic Time Warping
- 1962 : (3) IBM Shoebox can understand 16 English words
- 1969 : (1) Internet
- 1970s : (2) Hidden Markov Models
- 1971 : (1) Harpy created at Carnegie Mellon University, can comprehend 1011 words and some phrases
- 1986 : (2) Multi-layer perceptron (3) IBM Tangora using Hidden Markov Model, predicts upcoming phonems in speech
- 1987–1995 : (2) Speech recognition with Neural Network
- 1995- 2009 : (2) Superseded by GMM
- 1999 : (1) Seaman
- 2002 : (2) Neural network feature
- 2006 : (2) Deep Network (Hinton, 2002) (3) The National Security Agency (NSA) starts using speech recognition to isolate key words in recorded speech
- 2008 : (3) Google launches a voice search app, bringing speech recognition to mobile devices
- 2011 : (1) Siri on iOS (3) Apple announces Siri, ushering in the age on the voice-enable digital assistance
- 2012 : (2) RNN for speech recognition
Bagaimana Speech Recognition bekerja
Setelah mengetahui jenis-jenis Speech recognition dan sejarah perkembanganya, hal menarik lainnya adalah bagaimana suara dapat diterjemahkan oleh sistem komputer? Beberapa tahap harus dilalui sebuah suara untuk menjadi teks yang memiliki arti.
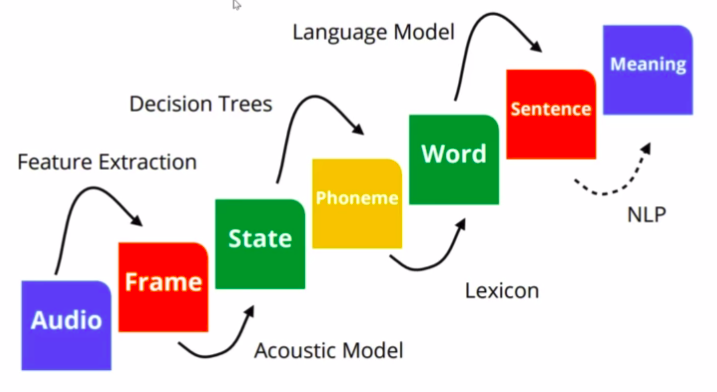
secara sederhana penterjemahan suara menjadi teks dapat digambarkan dengan diagram diatas. Cukup banyak tahapan yang dilaluinya hingga dapat menjadi sebuah sistem speech recognition. Penjelasan tentang ini akan dibahas pada postingan berikut-berikutnya, insyaallah.
Speech Technology Problem
Perkembangan teknologi ini memang sudah dari sangat lama dan banyak permasalah yang dapat diselesaikan dengannya sampai saat ini. Akan tetapi masih banyak peneliti yang melakukan penelitian agar sebuah sistem ini semakin nyaman digunakan, yang artinya sebuah sistem harus mendekati kemampuan manusia untuk melakukan komunikasi. Ada beberapa permasalah yang berkaitan dengan speech yang masih terus dikaji.
# Automatic Speech Recognition:
- Spontaneous and read speech
- Large Vocabulary
- In noise
- Low resources
- Far-field
- Accent-independent
- speaker adaptive
# Text to speech
- Low resources
- Realistic prosody
# Speaker Identification
# Speech enhancement
# Speech separation
Aplikasi Speech Recognition
Masih banyaknya permasalahan yang ada pada teknologi ini tidak membatasi kasus-kasus dikehidupan nyata untuk diselesaikan. Banyak kasus dibeberapa bidang yang sudah bisa diselesaikan oleh speech recognition.
- Dictation : merupakan pengunaan yang paling banyak saat sekarang ini. Termasuk transkripsi untuk bisnis, legal, dan kebutuhan medis. Bagian yang menantang adalah penggunaan kata-kata spesial yang harus ditambahkan pada setiap domain penggunaannya, misal kata-kata unik dari kedokteran harus ditambahkan untuk penggunaan untuk transkripsi medis.
- Command and control : sistem ini didesain untuk melakukan sebuah fungsi dan aksi untuk melakukan perintah kepada sistem lain. Contoh ucapan yang seperti “nyalakan lampu”, “mainkan musik pop”, dan sebagainya
- Wearables : penggunaan yang melibatkan perangkat tambahan berupa device yang melekat / dekat dengan pengguna, sehingga digunakan untuk melakukan perekaman suara maupun perintah suara.
- Disabilities : seseorang yang memiiki keterbatasan untuk melakukan suatu kegiatan karena tidak berfungsinya alat indra pada dirinya, dapat menggunakan sistem ini untuk mempermudah aktivitasnya. Seperti mengetik menggunakan suara atau membaca tulisan dari apa yang dikatakan seseorang.
- Embedded Application & robotics : sistem ini dapat membatu manusia untuk melakukan perintah langsung kepada perangkat. Contohnya: perintah sederhana untuk menyalakan televisi.
- Call center & IVR : banyak bisnis sekarang ini menggunakan teknologi untuk meningkatkan pelayanan dari setiap lininya, termasuk untuk Call Center & IVR. Kecepatan respon dan pelayanan yang akan meningkatkan kepuasa bagi konsumennya.
- Medical : pembuatan rekam medis yang dilakukan secara otomatis, dapat meningkatkan perhatian dan fokus dokter terhadap pasiennya. Sehingga, ketika pasien berbicara/berkonsultasi dengan dokter, dokter hanya tinggal fokus kepermasalah utama tentang pasien tersebut.
- Education : sistem ini dapat membantu seorang siswa untuk meningkatkan keampuan membaca dan berbicara dengan cara membuatnya melakukan dengan lantang.
- Television : sistem pembuatan teks secara otomatis, dapat membantu penyedia saluran televisi maupun pembuat film untuk membantu penontonnya mengerti lebih dalam tentang alur dari cerita yang mereka tonton.
- Car navigation : ketika berkendara seseorang tidak memiliki kesempatan lain untuk melakuka aktivitas lain. Voice command dapat membantu pengendara memberikan perintah langsung kepada sistem.
- Mobile Apps : mudahnya membawa perangkat handphone dalam setiap kegiatan manusia sekarang ini, menjadikan smartphone dibuat unutk dapat melakukan banyak kegiatan, termasuk voice command dan voice-to-voice translation.
References:
(https://www.youtube.com/watch?v=HyUtT_z-cms&t=1514s)
(http://www.ts.ip.titech.ac.jp/shinot/lectures/asrintro/asr-1.pdf)
Introduction
Speaker dependent systems are designed around a specific speaker. They generally are more accurate for the correct…www.tldp.org
Speaker dependent systems are designed around a specific speaker. They generally are more accurate for the correct…www.tldp.org
No comments:
Post a Comment