
Learning Speech Recognition (part 1)
Pada Intro telah dibahas tentang Speech Recognition secara umum. Part 1 ini akan dikenalkan perkembangan dari beberapa metode yang digunakan. Harapannya, artikel ini dapat memberikan pandangan secara umum bagaimana Speech Recognition bekerja.
Pendekatan untuk Pattern Matching di Speech Recognition
Sebelum membahas komponen yang terdapat pada speech recognition, ada baiknya membahas tentang metode atau pendekatan apa saja yang dapat digunakan untuk melakukan penterjemahan suara ke text. Sebenarnya metode yang digunakan ini memiliki hubungan dengan komposisi komponen yang digunakan. Terdapat lima metode yang akan coba dibahas disini. (link)
- Pendekatan Template-based
Metode yang digunakan yaitu dengan cara memcocokkan suara yang tidak dikenal dengan sekompulan suara yang sudah direkam sebelumnya.
kelebihan : simple dangan melakukan implementasiannya, kesalahan karena segmentasi atau klasifikasi unit variabel yang lebih kecil secara akustik seperti fonem dapat dihindari, dan memiliki model kata yang akurat.
kekurangan : tidak bisa untuk Continuous speech recognition, model pre-rekaman suara fixed, proses komputasi yang tidak murah sejalan dengan pemanbahan kosakata.
2. Pendekatan Knowledge-Based
Pada metode ini sistem memiliki informasi tentang linguistik, fonetik dan spektogram. Informasi tersebut kemudian dijadikan fitur untuk dibuat sistem klasifikasinya. Setelah model terbentuk, terdapat mesin inferensi untuk mengimplementasikan decision tree dan mengklasifikasikan aturan yang ada.
kelebihan: pemodelan terhadap suara dilakukan secara eksplisit
kekurangan : sulit diimplementasikan dan tidak praktis serta tidak otomatis
3. Pendekatan Neural Network-Based
Metode ini menggunaakan Neural Network dalam pembuatan pemodelan untuk pengenalan suara. Jaringan saraf tiruan dalam proses pengenalan ucapan dapat dibagi menjadi bidang-bidang berikut: Pertama meningkatkan kinerja jaringan saraf tiruan. Kedua, dapat digunakan untuk mengembangkan sistem hybrid gabungan. Ketiga, metode matematika mewakili sifat unik dari jaringan saraf dan diterapkan pada bidang proses pengenalan ucapan.
kelebihan: lebih baik pada suara yang kualitas rendah, berisik, dan pembicara yang independen.
kekurangan : tidak lebih baik dari HMM ketika kosa kata yang besar.
4. Pendekatan Dynamic Time Warping (DTW) Based
Metode ini memungkinkan sistem untuk menemukan kecocokan optimum terhadap dua sekuen yang diberikan pada batasan tertentu.
kelebihan : digunakan untuk isolated word recognition dan dapat dimodifikasi ke recognize connected words.
kekurangan : tidak digunakan untuk Continuous speech recognition.
5. Pendekatan Statistical- Based
Metode ini melakukan perhitungan secara statistik dengan menggunakan metode pelatihan. Sekarang ini Speech recognition didasarkan pada akustik statistik dan Language Model. Hidden Markov Model (HMM) merupakan metode yang paling banyak digunakan dan menjadi populer. Keuntungan dari HMM ini dapat mengurangi secara signifikan waktu dan kompleksitas dari proses pengenalan dari kosakata yang besar. Penjelasan-penjelasan selanjutnya akan banyak dibahas pembahasan tentang pengenalan ucapan secara statistik dan NN based.
kelebihan : dapat dilakukan unutk kosakata yang besar.
kekuangan : memerlukan data dengan jumlah yang cukup besar untuk mendapatkan hasil yang baik
Statistical Speech Recognition
Sedikit lebih dalam pembahasan tentang metode ini. Bagaimanakan secara matematis speech recognition bekerja? Pada sistem ini sistem menggunakan probability distribution untuk modelnya.
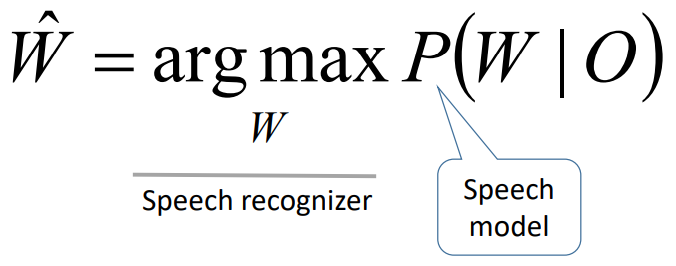
dengan menggunakan teorema bayesian, probability terbagi menjadi dua.

karena P(O) tidak tergantung pada proses memaksimalkan W, jadi dapat diabaikan.
Deskripsi:
- O : input fitur akustik
- W : huruf atau kata yang akan di recognize

Akustik Model dan Language Model
Perhitungan dari akustik model dan language model mungkin akan berbeda pada setiap kasus yang ada. Pada Intro (artikel pertama) telah dibahas tentang beberapa jenis speech recognition berdasarkan tipe utterance-nya. Setiap kasus memiliki penyelesaiannya tersendiri.
beberapa contoh metode untuk melakukan proses penyelesaian dari akustik model yaitu: Gaussian distribution, Gaussian mixture model, HMM, DNN, dsb. (link) (link)
sedangkan untuk language model, yaitu: Categorical distribution, N-gram, dsb.
penjelasan lebih lanjut tentang akustik model dan language model akan dibahas pada bahasan tersendiri.
Berikut beberpa sistem pengenalan ucapan berdasarkan jenis utterance-nya :
- Vowel recognition (GMM)
O: feature vector dari sebuah single frame
W: satu dari vowels (a,i,u,e,o)
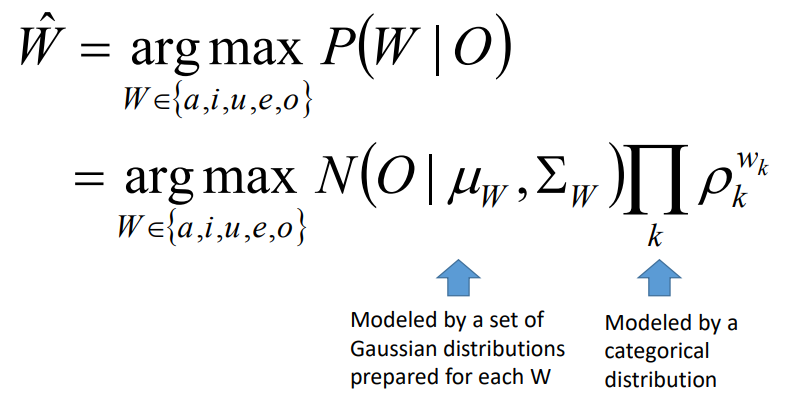
Akustik model : Gaussian distribution
language model : Categorical distribution
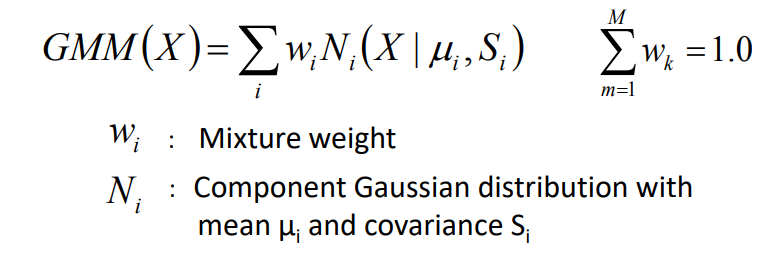
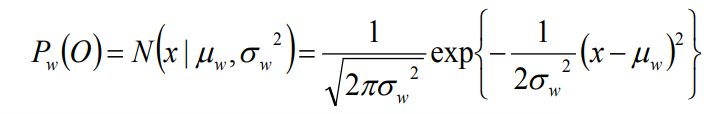
2. Phone recognition (HMM)
O: sebuah urutan feature vectors dari sebuah segmentasi pada sebuah phonem dari ucapan
W: satu dari kumpulan phonem sebuah bahasa
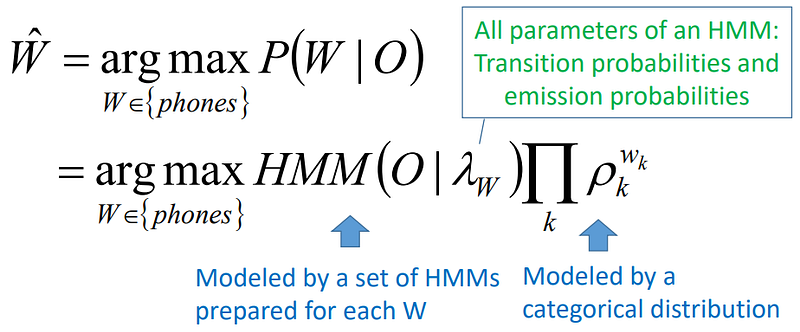
akustik model : HMM
language model : Categorical distribution
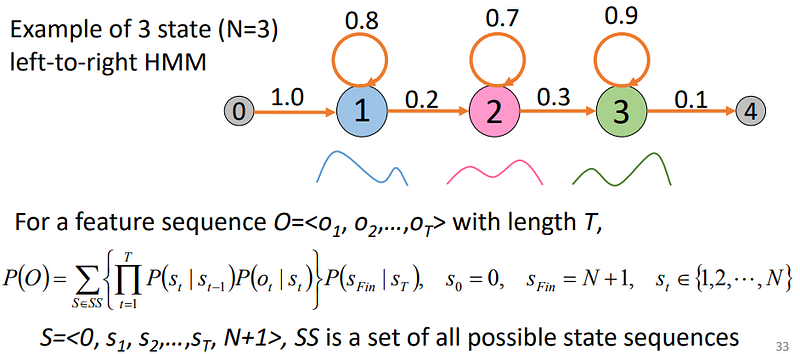
3. Isolated word recognition
O: sebuah urutan dari feature vector dari sebuah segmentasi sebuah kata dalam ucapan
W: satu dari kata dalam kosakata

akustik model : HMM
language model : Categorical distribution
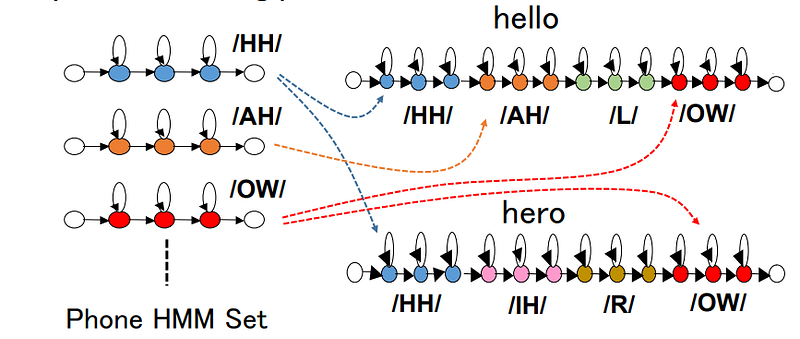
4. Continuous speech recognition
O: Sebuah urutan dari feature vectors dari sebuah ucapan
W: urutan kata dari sebuah ucapan

akustik model : HMM
language model : N-gram
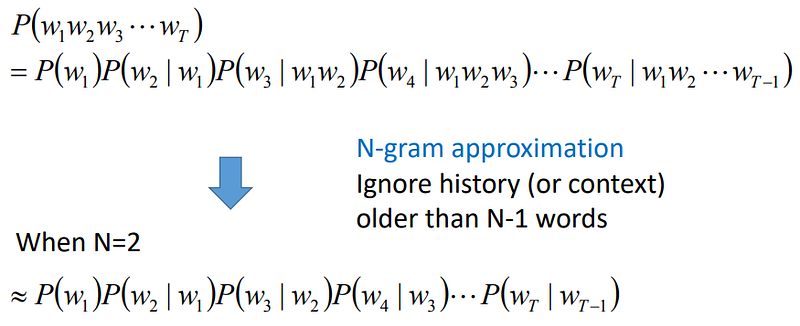
Bagaimana cara menghitungnya…
- Soal 1
jika diketahui P(O|V) merupakan accoustic model dan P(V) adalah language model, dan diberikan table log likelihoods seperti pada table. berapakah nilai maksimal dari W

import numpy as np
am = np.array([-13.4, -10.5, -30.1, -15.2, -17.0]) lm = np.array([-1.61, -2.30, -1.61, -1.39, -1.39])
score = np.multiply(am, lm) print(score)
maxi = score.argmax()
print("index argmax: ", maxi)
print("value argmax: ", score[maxi])
result:
[ 21.574 24.15 48.461 21.128 23.63 ]
('index argmax: ', 2)
('value argmax: ', 48.461000000000006)
2. soal 2
tabel dibawah ini menunjukan nilai bi-gram dari sebuah LM. Berapa nilai dari susunan kata berikut: “Start today sunny today sunny End” dan “Start today today sunny sunny End”
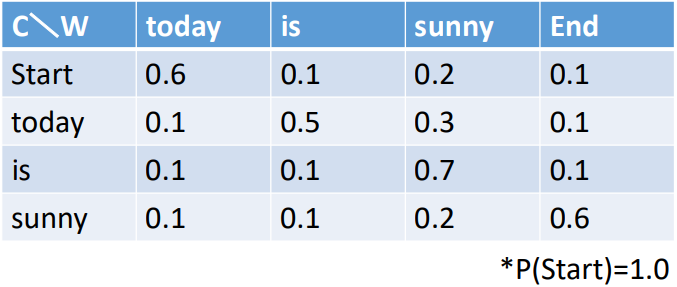
“Start today sunny today sunny End” = 1.0 * 0.6 * 0.3 * 0.1 * 0.3 * 0.6 = 0.00324
“Start today today sunny sunny End” = 1.0 * 0.6 * 0.1 * 0.3 * 0.2 * 0.6 = 0.00216
No comments:
Post a Comment