
Learning Speech Recognition (part 2)
Pada part 1, telah dibahas mengenai pengenalan awal speech recognition. Mulai dari definisi, jenis-jenis, history, penggunaan hingga bagaimana speech recognition bekerja. Artikel part 2 ini akan coba dibahas tentang komponen penyusun sistem speech recognition.
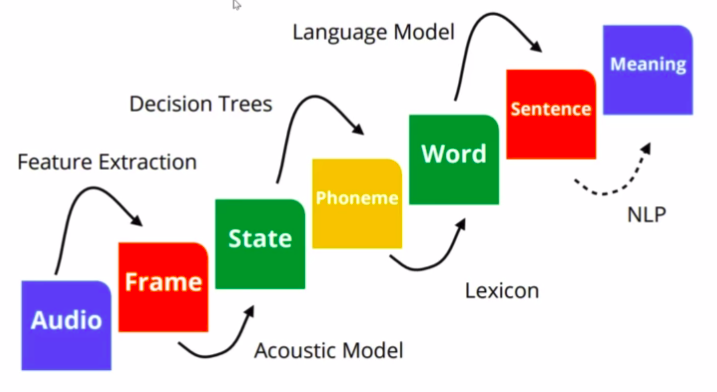
seperti yang dilihat dari gambar diatas, sistem penyusun dari speech recognition memiliki komponen yang lumayan banyak. Mulai dari audio yang direkam hingga menghasilkan sebuah teks. Masing-masing komponen dilakukan proses yang nantinya akan menjadi komponen lain. proses-proses ini yang masih terus dikaji untuk dilakukan pembaharuan-pembaharuan yang lebik mutakhir, agar menghasilkan proses yang efisien dan akurasi yang baik. Pembahasan selanjutnya akan dijabarkan proses-proses yang terjadi dari setiap komponen. insyaallah.

Representasi suara
- Pendengaran manusia ~50Hz — 20kHz (lebih umum pengetahuan tentang pendengaran manusia dimulai dari frekuensi 20Hz)
- musik 50Hz — 15kHz
- Suara manusia ~85Hz — 8kHz
- Suara telefoni yang memiliki samping 8kHz : 300Hz — 4kHz
- speech processing kontemporer lebih banyak menggunakan 16kHz 16bits/sample
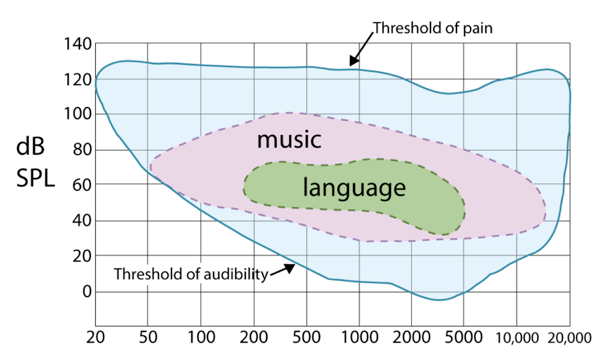
dari sini diketahui bahwa, pada suatu ketika seseorang dapat mendengar suatu suara/rekaman dengan baik. Akan tetapi ketika suara tersebut dimasukkan ke sebuah sistem rekognisi suara, sistem tidak dapat mengeluarkan transkripsi dengan baik. Hal itu dapat terjadi, dimungkinkan, karena perbedaan frekuensi yang ada.
Bagaimana suara manusia terbentuk
Suara yang dihasilkan oleh manusia memiliki proses yang unik untuk diketahui. Berikut sedikit ilustrasi bagaimana suara terbentuk.
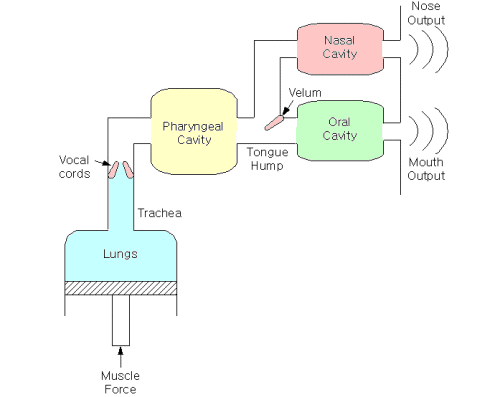
- gelombang terbentuk dari perubahan tekanan udara
- direalisasikan melalui eksitasi dari pita suara
- dimodulasikan oleh saluran vokal
- dimodulasikan oleh artikulator (lidah, gigi, bibir)
- vowels diproduksi dengan sebuah saluran vokal yang terbuka
- konsonan adalah penyempitan saluran vokal
- dikonversi ke tegangan melalui microphone
- disampling menggunakan analog to digital converter
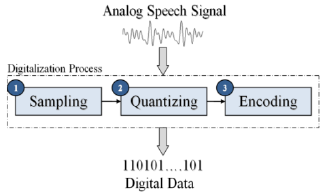
Mengetahui sifat dan jenis suara yang ada, memudahkan untuk mengetahui proses penerjemahan suara yang direkam. Suara manusia tidak dapat langsung diolah oleh komputer. Maka dari itu harus diubah kesebuah representasi agar komputer dapat mengolahnya, yaitu mengubahnya dari analog ke representasi digitallalu dilakukan ekstraksi fitur terhadap suara tersebut. Tujuan dari ekstraksi fitur suara, yaitu untuk:
- membantu meningkatkan performa dari pattern recognition
- mengurangi memory yang tidak perlu dan biaya pemprosesan
- mencari sekumpulan parameter dari sebuah utterance yang memiliki korelasi dengan sinyal suara
- menentukan informasi yang relevant dan menghilangkan informasi yang tidak dibutuhkan
Proses ekstraksi fitur pada suara
lalu bagaimana ekstraksi fitur pada suara untuk speech recognition dilakukan? secara umum, berikut proses ekstraksi fitur dilakukan:
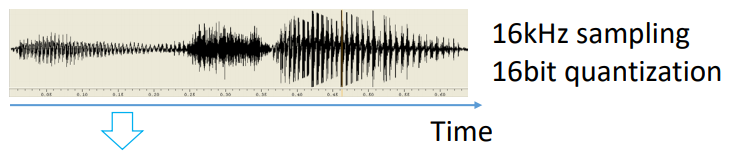
pastikan sampling dan quantizing dari suara sudah dengan format yang benar. Biasanya untuk speech recognition digunakan sample rate 16kHz dan nilai quantizing 16 bit.
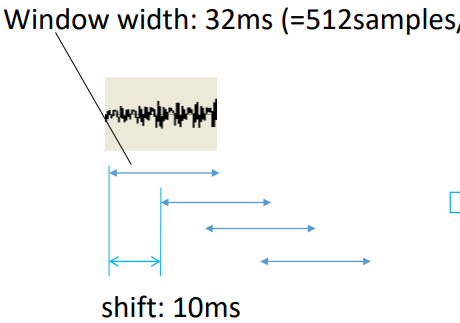
Selanjutnya, sinyal dibagi menjadi untuk dilakukan ekstraksi fitur. Komponen ekstraksi fiturnya tediri dari lebar (window width), shifting dan overlaping. penentuan shifting dan window width berbeda-beda, akan tetapi pada gambar diatas dilakukan shifting sebesar 10ms, dengan window width 32ms, dan overlaping sinyal sebesar 22ms.
pada presentasi Andrew (link) sekitar menit ke 12–13, mencontohkan melakukan pengolahan FFT dengan shifting sebesar 10ms, window width 35ms, dan overlapping sebesar 25ms. Jadi nilai-nilai ini masih bisa berbeda dengan kasus yang lainnya.
Biasanya lebar dari sinyal yang dijadikan frame berkisar antara 20ms–40ms per frame. Hal tersebut dikarenakan, jika lebar terlalu pendek maka tidak mendapatkan estimasi spektral yang baik, dan juga ketika lebarnya terlalu besar maka perubahan terlalu sering disetiap frame yang ada. (link)
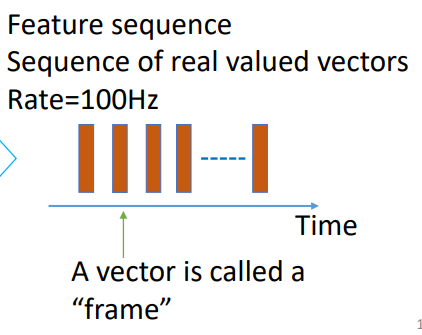
tahap terakhirnya adalah terbentuknya “frame” yang direpresentasikan dengan vector. Frame ini akan digunakan untuk proses selanjutnya dalam membuat model akustik.
Metode ekstraksi fitur dalam speech recognition
Terdapat banyak metode untuk melakukan ekstraksi fitur pada speech recognition, yang masing-masing memiliki kelebihan dan kekurangannya dan juga perbedaan property yang digunakan. Berikut merupakan beberapa metode untuk melakukan ekstraksi fitur:
- Principal Component Analysis (PCA)
- Linear Discriminate Analysis (LDA)
- Independent Component Analysis (ICA)
- Linear Predictive Coding
- Filter Bank Analysis
- Mel-frequency Cepstrum Coefficients (MFCC)
- Kernel based feature extraction method
- Wavelet
- Cepstral Mean Subtraction
- RASTA Filtering
Pada kesempatan kali ini mungkin akan lebih banyak dibahas tentang ekstraksi fitur menggunakan Mel-frequency Cepstrum Coefficient (MFCC). Akan tetapi, jika ada yang ingin mengetahui lebih lanjut pembahasan singkat tentang perbandingan setiap metode dapat dilihat pada paper tautan berikut (link).
Mel-frequency Cepstrum Coefficients (MFCC)
Pada MFCC ini proses dilakukan pada power spektrum dari suara yang diproses menggunakan implementasi dari Fourier Analysis. Pada Fourier analysis ini kita juga membahas tentang Fourier Transform. Kekurangan dari MFCC ini tidak terlalu robust pada tambahan noise sekarang ini, tetapi dapat di reduce dengan menormalisasi nilainya.
ketika mempelajari lebih lanjut tentang proses yang terjadi untuk mendapatkan MFCC, ada beberapa hal yang menjadikan sedikit bingung untuk orang awam (termasuk saya). Tedapat perbedaan pada salah satu komponen yang ada pada prosesnya. Jika melihat pada diagram prosesnya, terdapat satu bagian yang terdapat perbedaan dibeberapa referensi, yaitu penggunaan FFT, DFT, dan DCT.
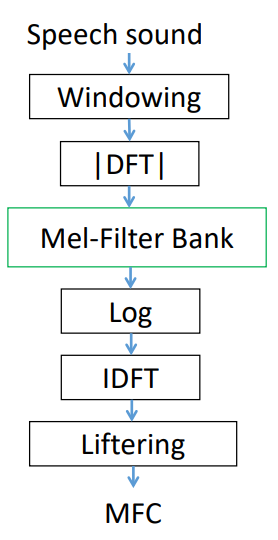
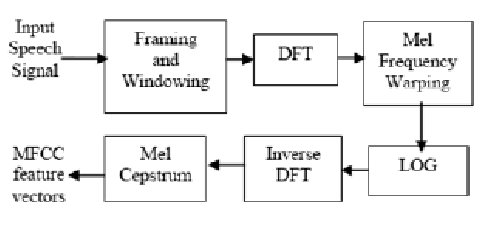
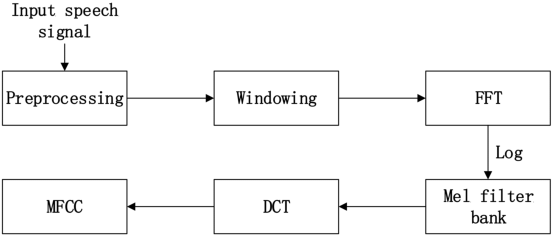
Setelah mencoba untuk sedikit mencari, akhirnya mendapatkan penjelasan yang cukup dipahami, tentang perbedaan ketiga jenis metode tersebut. Berikut link-nya (link). Ketiga algoritma itu sama-sama merupakan sebuah transformasi linier yang memiliki input-an sebuah sinyal (complex/real) dari sebuah panjang sinyal tertentu dan menghasilkan output.
- DFT (discrete Fourier Transform): teorema pada pengolahan sinyal kompleks.
- FFT : algoritma dari DFT
- DCT (discrete cosine transform): teorema pada pengolahan sinyal real.
setelah melihat di (satu) forum yang ada, lebih banyak orang yang merekomendasikan menggunakan DCT dibandingkan yang lainnya. (link1) (link2). Hal tersebut dapat terlihat dari banyaknya tools populer yang menggunakan DCT pada bagian dari ekstraksi fiturnya.
Ekstarksi fitur (MFCC) pada tools yang ada
- Pocketsphinx (link) : 13 columns per frame
- kaldi (link) : FFT — DCT; 23 triangular overlapping bins and 13 coefficients; 25 ms frames shifted by 10ms each time
- slaney (link) : FFT — DCT ;
- htk (link) (link): FFT — DCT; 26 channels and 12 MFCC coefficients; shifted by 10ms each time
- librosa (link): DCT;
- other (link1) (link2): FFT — DCT
No comments:
Post a Comment