
Pada postingan kali ini saya akan mencoba menuliskan sedikit catatan tentang pengalaman saya mengikuti Pytorch Challange yang diadakan Udacity. Alhamdulillah saya mendapatkan kesempatan ini, jadi saya akan mencoba meringkas sedikit catatan penting tentang Fundamental Neural Network.
1. Linear Boundary





















Multi class:

Steps:








mengkalkulasikan ulang bobot dari setiap nilai, untuk di update, agar menghasilkan prediksi selanjutnya yang lebih baik



 ReLU:
ReLU:




1. Linear Boundary

sumber: udacity
pada materi pertama kita akan belajar bagaimana klasifikasi itu bekerja. Gambar diatas memberikan informasi sekumpulan data penerimaan mahasiswa yang dipisahkan oleh sebuah garis (w1x1+w2x2+b), dimana data berwarna biru merupakan data dengan label mahasiswa yang diterima dan data berwarna merah merupakan data dengan label mahasiswa yang ditolak.
rumus umum dari garis pemisah itu adalah : Wx + b = 0
dimana:
W : vektor dari bobot
x : vektor dari titik yang ada (axis x = nilai test; axis y = nilai grade)
b : bias
kita akan membuat sebuah prediksi dari sebuah data, apakah masuk kedalam kelompok biru (diterima) ataupun merah (ditolak) dengan sebuah fungsi:
^y = 1 if Wx + b >= 0
y topi akan bernilai satu (diterima) jika fungsi vektor W (dot) vektor x ditambah b lebih dari samadengan 0
^y = 0 if Wx + b < 0
y topi akan bernilai nol (ditolak) jika vektor W (dot) vektor x ditambah b kurang daro 0
contoh:
Soal:
Anak yang memiliki nilai 8 dan grade 7 apakah akan diterima atau ditolak pada sebuah penerimaan universitas dengan fungsi garis pembatasnya adalah 2x1 + x2 - 16=0 ?
jawab:
2x1 + x2 - 16 = 2 . 8 + 1 . 7 - 16 = 16 + 7 - 16 = 7
karena hasil perhitungannya 7, dan 7 lebih dari 0. maka label yang pas untuk data tersebut adalah 1 (diterima)
Dari perhitungan diatas, kita mengetahui data yang diberikan merukana data berdimensi 2. Lalu bagaimana jika data yang dimiliki lebih dari 2 dimensi, bukan hanya nilai test dan grade tapi ada data lain?

persamaannya tetap sama seperti 2 dimensi, yaitu Wx + b = 0
dimana kita tahu untuk perkalian matrik, column matriks pertama harus sama dengan row matrik kedua, sehingga menghasilkan bentuk matriks seperti row matriks pertama dan column matrix kedua:
vektor W : [m . n]
vektor x : [n . o]
W . x = [m . n][n . o] = [m . o]
untuk penjumlahan matriks, kedua matriks harus memilikin bentuk yang sama:
a + b = [m . o] + [m . o] = [m . o]
2. Perceptron

Pada bahasan selanjutnya, kita dikenalkan dengan perceptron, yaitu bentuk sederhana dari Neural Network. Dimana dari permasaan Linear sederhana (bahasan 1, diatas) kita coba buat graph nya sehingga Neural Network mudah untuk dipahami.


disini kita mencoba untuk memahami arsitektur dari Neural Network. arsitektur ini terdiri dari:
Input -> Equation -> Activation -> Prediction
Input:
1. x1, x2, ...., xn = data
2. w1, w2, ...., wn = bobot
3. b = bias
Equation:
Wx + b = persamaan linear
Activation:
[1, 0] = step function
Prediction:
[Yes, No]
3. Train, Learning rate, Epoch
Bahasan ketiga ini kita dipandu untuk mengetahui bagaimana sebuah data di latih untuk membuat sebuah model.
jika terdapat sebuah titik (merah) yang berada pada wilayah biru, dimana titik itu salah belum tepat untuk di klasifikasikan. bagaimana kita dapat melakukan perhitungan agar titik merah berada pada wilayah merah?

mudah nya kita dekatkan saja langsung ke titik tersebut, dengan melakukan perhitungan titik dengan garis. Tetapi cara ini sebenarnya kurang pas, dikarenakan garis akan bergeser cukup jauh ke atas titik. terlebih jika sudah terdapat banyak titik.

Disini kita dikenalkan dengan "Learning rate", dimana garis di dekatkan sedikit demi sedikit ke titik yang ingin dituju. Dengan :
learning rate 0.1
titik yang akan dituju adalah (4,5),
garis 3x1 + 4x2 - 10 = 0
akan menjadi 2.6x1 + 3.5 x2 - 10.1 = 0
Hasilnya garis tersebut semakin mendekati titik.
Epoch sendiri merupakan, berapa kali proses tersebut dilakukan agar titik dapat berada dekat dan dibawah garis.
berikut merupakan pseudocode untuk perceptron algoritma.

if y[i]-y_hat == 1:
W[0] += X[i][0]*learn_rate
W[1] += X[i][1]*learn_rate
b += learn_rate
elif y[i]-y_hat == -1:
W[0] -= X[i][0]*learn_rate
W[1] -= X[i][1]*learn_rate
b -= learn_rate
4. Error Function
untuk mengetahui seberapa perlu lagi kita melakukan training data dan seberapa baik model yang sudah kita buat, terdapat sebuah nilai yang dapat kita jadikan patokan. Yap, Error function dapat digunakan mnegetahui sebarapa jauh lagi sebuah titik dari model yang sudah di bentuk.

di bahasan ini, kita mengetaui bahwa error function haruslah dalam nilai yang continuous. kenapa?


kerena jika kita memiliki data lalu kita coba melakukan sedikit perubahan dengan melakukan training dengan learning rate yang kecil, sistem tidak dapat membedakan jika sebenarnya ada perubahan garis yang semakin mendekari titik yang salah diklasifikasikan.

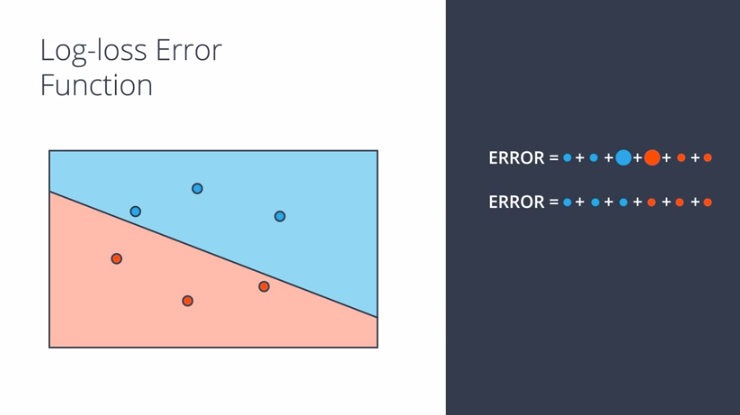
dengan begitu, error rate tersebut haruslah merupakan jarak yang continuous, agar dapat diketahui jika memang ada perubahan padanya.


fungsi continuous dari sebuah error rate adalah fungsi Sigmoid dengan persamaan:
sigmoid(x) = 1/(1+e-x)
5. Softmax
softmax function merupakan function mirip dengan sigmoid. hanya saja sofmax digunakan untuk aktivasi pengkelasan 3 atau lebih kelas.


softmax ini digunakan untuk menghindari pembagian dari angka negatif, semua angka haruslah menjadi angka positif, dari 0 hingga seluruh angka positif. Karena mengharuskan seluruh nilai positif, maka fungsi exponensial (exp) diperlukan. dengan begitu seluruh nilai akan menjadi positif sebelum di proses mencari probabilitas.
6. Maximum Likelihood
metode ini digunakan untuk mencari probability paling tinggi dari probability seluruh data yang ada. Terkadang sebagian dari memiliki probabilitas yang berbeda-beda dengan sebagain data yang lain. hal ini membuat kesulitan dalam menentukan kemungkinan secara general. Hal tersebut kita lakukan untuk melakukan evaluasi sekaligus melakukan improvement terhadap akurasi model yang telah kita buat.
7. Cross Entropi
Untuk dapat memaksimumkan probability, cara mudahnya kita harus mengecilkan error function yang ada. Sedangkan hubungan antara Probability dengan Error Funtion adalah Cross-Entropi.
semakin besar Pobability akan semakin bagus model yang di bentuk.
sedangkan semakin kecil cross-entropi dari sebuah model, maka model itu juga akan semakin baik.

Persamaan

Contoh:
CE = 0.69 lebih baik dari pada CE = 5.12
8. Logistic Regression

Multi class:

Steps:

9. Different between Perceptron and Gradient Descent


Perceptron:
if misclassified : tell the line > ome closer
if correct : do nothing
Gradient Descent:
if misclassified : tell the line > come closer
if correct : tell the line > go far away
10. Non-Linear Model
mulai dari setiap linear grafik:

grafik satu kita boboti 7 sedangkan grafik 2 kita boboti 5 (kita sesuaikan saja)

simplifikasi dari grafik diatas:

penambahan bias dan activation:

11. Backpropagation
Feedforward: membuat prediksi dari setiap data yang di train

mengkalkulasikan ulang bobot dari setiap nilai, untuk di update, agar menghasilkan prediksi selanjutnya yang lebih baik

12. Underfitting and Overfitting
pada bahasan kali ini kita diajarkan bagaimana melakukan training data yang tepat. terdapat 2 hal yang dapat membuat model menjadi tidak bagus, yaitu underfitting dan juga overfitting. kita harus menghindari kedua model data tersebut

13. Other Activation Function
Problem pada sigmoid function:

Hiperpolic Tangent:


Arsitektur setelah dilakukan perubahan fungsi aktivasi:


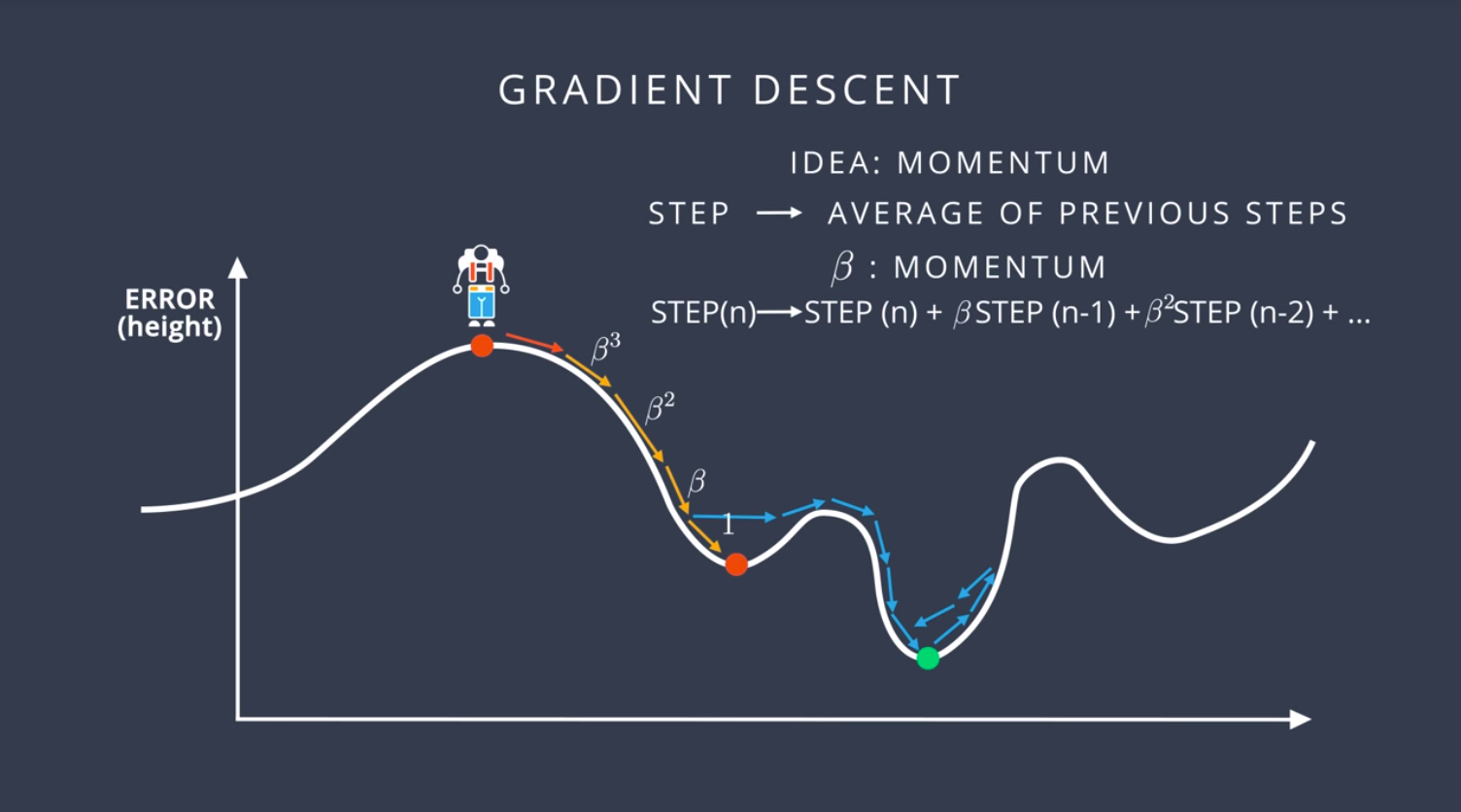
14. Momentum
No comments:
Post a Comment