
Pada subbab kali ini kita diajarkan untuk mengetahui lebih jauh tentang RNN serta LSTM. RNN dibuat secara khusus untuk membatu sistem mempelajari sequence dari sebuah data. dimana sequence data di proses ke hidden state dan kemudian akan menghasilkan output sequence yang lainnya. Sedangkan Long Short Time Memory (LSTM) merupakan improvement dari RNN yang dapat mengingat data sebelumnya dan data dari waktu yang lama sebelumnya.
A. Konsep
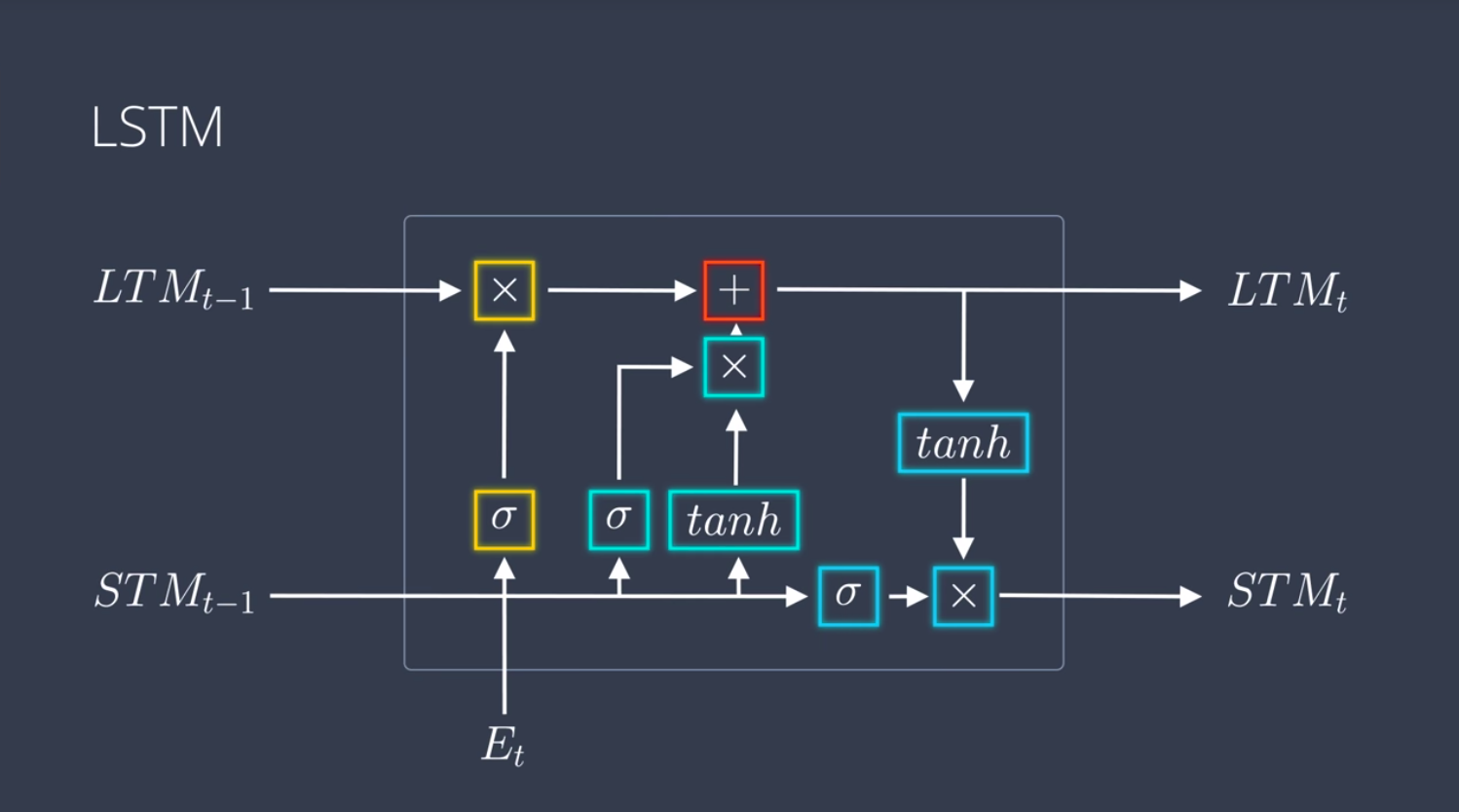
1. Basic LSTM

secara umum ada beberapa komponen yang terdapat di arsitektur LSTM, yaitu:
input, yang terdiri dari data sebelumnya (Long Term Memory dan Short Term Memory) serta masukkan pada event sekarang. Terdapat juga komponen output, yaitu LTM baru dan STM baru. Didalamnya terdapat beberapa gate, pertama ada Forget Gate, Learn Gate, Remember Gate, dan juga Use Gate.
 Secara matematik terdapat beberapa perhitungan yang berada di dalam setiap Gate, yang merupakan gabungan dari beberapa fungsi dan fungsi aktivasi-nya. Dibawah ini akan sedikit dijelaskan untuk setiap Gate yang ada.
Secara matematik terdapat beberapa perhitungan yang berada di dalam setiap Gate, yang merupakan gabungan dari beberapa fungsi dan fungsi aktivasi-nya. Dibawah ini akan sedikit dijelaskan untuk setiap Gate yang ada.
a. Learn Gate
 (1)
(1) (2)
(2)
 (3)
(3) (4)
(4)
pada Gate ini inputan terdiri dari STM dan Event, kemudian masuk ke fungsi combine yang mengkombinasikan kedua iput tersebut. setelah itu masuk ke fungsi ignore yang menghilangkan sedikit ingetan pada LTM, lalu menghasilkan output. secara matematik dapat di terjemahkan kedalam grafik dibawah.

b. Forget Gate
 pada Forget Gate, Gate ini yang menentukan informasi mana yang harus di hapus dan yang harus di pertahankan dari informasi yang diberikan oleh LTM.
pada Forget Gate, Gate ini yang menentukan informasi mana yang harus di hapus dan yang harus di pertahankan dari informasi yang diberikan oleh LTM.
 secara matematik, dapat didefinisikan oleh fungsi diatas. Dimana input LTM harus dioperasikan dengan sebuah forget vactor. Forget vaktor itu dihasilkan oleh operasi dari STM dan Event.
secara matematik, dapat didefinisikan oleh fungsi diatas. Dimana input LTM harus dioperasikan dengan sebuah forget vactor. Forget vaktor itu dihasilkan oleh operasi dari STM dan Event.
c. Remember Gate
 Gate ini di fungsikan untuk mengingat semua inputan dari semua inputan.
Gate ini di fungsikan untuk mengingat semua inputan dari semua inputan.
 pada persamaan matematisnya, merupakan penjumlahan dari keluaran yang dihasilkan oleh Forgate Gate dan juga Learn Gate.
pada persamaan matematisnya, merupakan penjumlahan dari keluaran yang dihasilkan oleh Forgate Gate dan juga Learn Gate.
d. Use Gate
 Tujuan pada gate ini yaitu untuk memprediksi suatu informasi inputan saat ini (Event) yang kemudian menghasikan prediksi yang diinginkan dengan membawa beberapa informasi tambahan dari ingatan sebelumnya. Secara fungsi matematis dapat ditulis dengan fungsi dibawah ini.
Tujuan pada gate ini yaitu untuk memprediksi suatu informasi inputan saat ini (Event) yang kemudian menghasikan prediksi yang diinginkan dengan membawa beberapa informasi tambahan dari ingatan sebelumnya. Secara fungsi matematis dapat ditulis dengan fungsi dibawah ini.

2. GRU, arsitektur RNN yang lainnya
 Pada arsitektur ini, singkatnya, Forget Gate dan Learn Gate disatukan menjadi Update Gate, kemudian hasilnya dilanjutkan dengan proses di Combine Gate. Pada arsitektur ini hanya dihasilkan satu outpu saja.
Pada arsitektur ini, singkatnya, Forget Gate dan Learn Gate disatukan menjadi Update Gate, kemudian hasilnya dilanjutkan dengan proses di Combine Gate. Pada arsitektur ini hanya dihasilkan satu outpu saja.
3. Implementasi pada Pytorch
a. Code di pytorch (Code)
import semua library yang dibutuhkan:
buat arsitektur RNN yang diinginkan:
Parameter method RNN adalah sebagai berikut:
- input_size : ukuran dari parameter input
- hidden_dim : jumlah dari fitur pada output RNN dan jumlah pada hidden state
- n_layers : jumlah layar pada RNN, umumnya 1-3 layar
- batch_first : whether or not the input/output of the RNN will have the batch_size as the first dimension (batch_size, seq_length, hidden_dim)
buat instance dari kelas RNN:
definisikan Loss dan Optimizer kriteria:
buat fungsi train:
lakukan training:
Jika kita ingin mengganti arsitekturnya (RNN, LSTM, GRU) kita dapat melihat pada dokumentasi pada pytorch: https://pytorch.org/docs/stable/nn.html#recurrent-layers
b. contoh kasus, Character-Level LSTM in PyTorch
sekarang kita mencoba untuk membuat sebuah model dari kasus untuk melanjutkan karakter dari sebuah input karakter yang diberikan. oya sekarang akan dibahas sebuah contoh dalam kasus teks prosesing. Beberapa tahap yang harus dilakukan adalah sebagai berikut:
(1) Load dataset
kita akan mengubah karakter ke angka, agar dapat di proses oleh komputer. Sekarang kita akan menentukan jumlah huruf yang unik yang ada dalam dataset. Setelah diketahui, masing-masing karakter akan di pasangkan dengan sebuah angka (Integer). Lalu seluruh teks di dataset kita uba menjadi angka seluruhnya.
 untuk dapat men-trainingkan data, kita diharuskan membuat data menjadi batch. Nantinya data akan di proses batch per batch.
untuk dapat men-trainingkan data, kita diharuskan membuat data menjadi batch. Nantinya data akan di proses batch per batch.
PEMBUATAN BATCH
(a) membuang beberapa teks, sehingga hanya memiliki mini-batch yang lengkap
setiap batch memiliki ukuran N x M karakter, dimana N merupakan jumlah batch (batch size) dan M merupakan panjang susunan (sequence length) atau M merupakan jumlah step dalam sebuah sequence. Sedangkan total jumlah batch, K, yang kita dapat tentukan dari panjang array karakter dibagi dengan jumlah karakter per batch. Total karakter yang akan di proses yaitu N x M x K
(b) splid data karakter ke N batch
ubahlah dimensi data menjadi N x (M * K). kita bisa gunakan numpy.reshape
(c) sekarang kita memiliki array ini. dan kita bisa melakukakan iterasi untuk mendapatkan mini-batch
pada tahap ini gita bisa melakukan iterasi dari 0 hingga (M * K), dimana peningkatannya dilakukan sebanyak squence length.
(4) one-hot-encoding
Input dari arsitektur RNN yang akan digunakan megharuskan membentuk data dalam bentuk one-hot-encoding. Maka kita akan coba mengubah dataset kita dalam bentuk on-hot-encoding agar dapat di proses. Karakter dari setiap dataset yang ada akan diubah menjadi sebuah vektor yang hanya terdiri dan hanya dua jenis nilai, yaitu 1 dan 0, dua jenis karakter ya dan bukan hanya dua nilai ([1, 0]).
dibawah ini merupakan contoh hasil encoding dalam one-hot-encoding:
A. Konsep
1. Basic LSTM

secara umum ada beberapa komponen yang terdapat di arsitektur LSTM, yaitu:
input, yang terdiri dari data sebelumnya (Long Term Memory dan Short Term Memory) serta masukkan pada event sekarang. Terdapat juga komponen output, yaitu LTM baru dan STM baru. Didalamnya terdapat beberapa gate, pertama ada Forget Gate, Learn Gate, Remember Gate, dan juga Use Gate.
a. Learn Gate
 (1)
(1) (2)
(2) (3)
(3) (4)
(4)pada Gate ini inputan terdiri dari STM dan Event, kemudian masuk ke fungsi combine yang mengkombinasikan kedua iput tersebut. setelah itu masuk ke fungsi ignore yang menghilangkan sedikit ingetan pada LTM, lalu menghasilkan output. secara matematik dapat di terjemahkan kedalam grafik dibawah.

b. Forget Gate


c. Remember Gate


d. Use Gate


2. GRU, arsitektur RNN yang lainnya

3. Implementasi pada Pytorch
a. Code di pytorch (Code)
import semua library yang dibutuhkan:
import torch
from torch import nn import numpy as np import matplotlib.pyplot as plt
buat arsitektur RNN yang diinginkan:
class RNN(nn.Module): def __init__(self, input_size, output_size, hidden_dim, n_layers): super(RNN, self).__init__() self.hidden_dim=hidden_dim # define an RNN with specified parameters # batch_first means that the first dim of the input and output will be the batch_size self.rnn = nn.RNN(input_size, hidden_dim, n_layers, batch_first=True) # last, fully-connected layer self.fc = nn.Linear(hidden_dim, output_size) def forward(self, x, hidden): # x (batch_size, seq_length, input_size) # hidden (n_layers, batch_size, hidden_dim) # r_out (batch_size, time_step, hidden_size) batch_size = x.size(0) # get RNN outputs r_out, hidden = self.rnn(x, hidden) # shape output to be (batch_size*seq_length, hidden_dim) r_out = r_out.view(-1, self.hidden_dim) # get final output output = self.fc(r_out) return output, hidden
Parameter method RNN adalah sebagai berikut:
- input_size : ukuran dari parameter input
- hidden_dim : jumlah dari fitur pada output RNN dan jumlah pada hidden state
- n_layers : jumlah layar pada RNN, umumnya 1-3 layar
- batch_first : whether or not the input/output of the RNN will have the batch_size as the first dimension (batch_size, seq_length, hidden_dim)
buat instance dari kelas RNN:
# decide on hyperparameters input_size=1 output_size=1 hidden_dim=32 n_layers=1 # instantiate an RNN rnn = RNN(input_size, output_size, hidden_dim, n_layers) print(rnn)
definisikan Loss dan Optimizer kriteria:
# MSE loss and Adam optimizer with a learning rate of 0.01 criterion = nn.MSELoss() optimizer = torch.optim.Adam(rnn.parameters(), lr=0.01)
buat fungsi train:
# train the RNN def train(rnn, n_steps, print_every): # initialize the hidden state hidden = None for batch_i, step in enumerate(range(n_steps)): # defining the training data time_steps = np.linspace(step * np.pi, (step+1)*np.pi, seq_length + 1) data = np.sin(time_steps) data.resize((seq_length + 1, 1)) # input_size=1 x = data[:-1] y = data[1:] # convert data into Tensors x_tensor = torch.Tensor(x).unsqueeze(0) # unsqueeze gives a 1, batch_size dimension y_tensor = torch.Tensor(y) # outputs from the rnn prediction, hidden = rnn(x_tensor, hidden) ## Representing Memory ## # make a new variable for hidden and detach the hidden state from its history # this way, we don't backpropagate through the entire history hidden = hidden.data # calculate the loss loss = criterion(prediction, y_tensor) # zero gradients optimizer.zero_grad() # perform backprop and update weights loss.backward() optimizer.step() # display loss and predictions if batch_i%print_every == 0: print('Loss: ', loss.item()) plt.plot(time_steps[1:], x, 'r.') # input plt.plot(time_steps[1:], prediction.data.numpy().flatten(), 'b.') # predictions plt.show() return rnn
lakukan training:
# train the rnn and monitor results n_steps = 75 print_every = 15 trained_rnn = train(rnn, n_steps, print_every)
Jika kita ingin mengganti arsitekturnya (RNN, LSTM, GRU) kita dapat melihat pada dokumentasi pada pytorch: https://pytorch.org/docs/stable/nn.html#recurrent-layers
b. contoh kasus, Character-Level LSTM in PyTorch
sekarang kita mencoba untuk membuat sebuah model dari kasus untuk melanjutkan karakter dari sebuah input karakter yang diberikan. oya sekarang akan dibahas sebuah contoh dalam kasus teks prosesing. Beberapa tahap yang harus dilakukan adalah sebagai berikut:
(1) Load dataset
# open text file and read in data as `text`
with open('data/anna.txt', 'r') as f:
text = f.read()kita akan mengubah karakter ke angka, agar dapat di proses oleh komputer. Sekarang kita akan menentukan jumlah huruf yang unik yang ada dalam dataset. Setelah diketahui, masing-masing karakter akan di pasangkan dengan sebuah angka (Integer). Lalu seluruh teks di dataset kita uba menjadi angka seluruhnya.
# encode the text and map each character to an integer and vice versa
# we create two dictionaries:
# 1. int2char, which maps integers to characters
# 2. char2int, which maps characters to unique integers
chars = tuple(set(text))
int2char = dict(enumerate(chars))
char2int = {ch: ii for ii, ch in int2char.items()}
# encode the text
encoded = np.array([char2int[ch] for ch in text])
PEMBUATAN BATCH
(a) membuang beberapa teks, sehingga hanya memiliki mini-batch yang lengkap
setiap batch memiliki ukuran N x M karakter, dimana N merupakan jumlah batch (batch size) dan M merupakan panjang susunan (sequence length) atau M merupakan jumlah step dalam sebuah sequence. Sedangkan total jumlah batch, K, yang kita dapat tentukan dari panjang array karakter dibagi dengan jumlah karakter per batch. Total karakter yang akan di proses yaitu N x M x K
(b) splid data karakter ke N batch
ubahlah dimensi data menjadi N x (M * K). kita bisa gunakan numpy.reshape
(c) sekarang kita memiliki array ini. dan kita bisa melakukakan iterasi untuk mendapatkan mini-batch
pada tahap ini gita bisa melakukan iterasi dari 0 hingga (M * K), dimana peningkatannya dilakukan sebanyak squence length.
(4) one-hot-encoding
Input dari arsitektur RNN yang akan digunakan megharuskan membentuk data dalam bentuk one-hot-encoding. Maka kita akan coba mengubah dataset kita dalam bentuk on-hot-encoding agar dapat di proses. Karakter dari setiap dataset yang ada akan diubah menjadi sebuah vektor yang hanya terdiri dan hanya dua jenis nilai, yaitu 1 dan 0, dua jenis karakter ya dan bukan hanya dua nilai ([1, 0]).
dibawah ini merupakan contoh hasil encoding dalam one-hot-encoding:
[[[0. 0. 0. 1. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 1. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0.]]]
ada 3 karakter (row), dengan sequence length sebanyak 8 (column)
def one_hot_encode(arr, n_labels): # Initialize the the encoded array one_hot = np.zeros((np.multiply(*arr.shape), n_labels), dtype=np.float32) # Fill the appropriate elements with ones one_hot[np.arange(one_hot.shape[0]), arr.flatten()] = 1. # Finally reshape it to get back to the original array one_hot = one_hot.reshape((*arr.shape, n_labels)) return one_hot
(5) Mendefinisikan Arsitektur dari RNNclass CharRNN(nn.Module): def __init__(self, tokens, n_hidden=256, n_layers=2, drop_prob=0.5, lr=0.001): super().__init__() self.drop_prob = drop_prob self.n_layers = n_layers self.n_hidden = n_hidden self.lr = lr # creating character dictionaries self.chars = tokens self.int2char = dict(enumerate(self.chars)) self.char2int = {ch: ii for ii, ch in self.int2char.items()} ## TODO: define the LSTM self.lstm = nn.LSTM(len(self.chars), n_hidden, n_layers, dropout=drop_prob, batch_first=True) ## TODO: define a dropout layer self.dropout = nn.Dropout(drop_prob) ## TODO: define the final, fully-connected output layer self.fc = nn.Linear(n_hidden, len(self.chars)) def forward(self, x, hidden): ''' Forward pass through the network. These inputs are x, and the hidden/cell state `hidden`. ''' ## TODO: Get the outputs and the new hidden state from the lstm r_output, hidden = self.lstm(x, hidden) ## TODO: pass through a dropout layer out = self.dropout(r_output) # Stack up LSTM outputs using view # you may need to use contiguous to reshape the output out = out.contiguous().view(-1, self.n_hidden) ## TODO: put x through the fully-connected layer out = self.fc(out) # return the final output and the hidden state return out, hidden def init_hidden(self, batch_size): ''' Initializes hidden state ''' # Create two new tensors with sizes n_layers x batch_size x n_hidden, # initialized to zero, for hidden state and cell state of LSTM weight = next(self.parameters()).data if (train_on_gpu): hidden = (weight.new(self.n_layers, batch_size, self.n_hidden).zero_().cuda(), weight.new(self.n_layers, batch_size, self.n_hidden).zero_().cuda()) else: hidden = (weight.new(self.n_layers, batch_size, self.n_hidden).zero_(), weight.new(self.n_layers, batch_size, self.n_hidden).zero_()) return hidden(6) buat method untuk trainingdef train(net, data, epochs=10, batch_size=10, seq_length=50, lr=0.001, clip=5, val_frac=0.1, print_every=10): ''' Training a network Arguments --------- net: CharRNN network data: text data to train the network epochs: Number of epochs to train batch_size: Number of mini-sequences per mini-batch, aka batch size seq_length: Number of character steps per mini-batch lr: learning rate clip: gradient clipping val_frac: Fraction of data to hold out for validation print_every: Number of steps for printing training and validation loss ''' net.train() opt = torch.optim.Adam(net.parameters(), lr=lr) criterion = nn.CrossEntropyLoss() # create training and validation data val_idx = int(len(data)*(1-val_frac)) data, val_data = data[:val_idx], data[val_idx:] if(train_on_gpu): net.cuda() counter = 0 n_chars = len(net.chars) for e in range(epochs): # initialize hidden state h = net.init_hidden(batch_size) for x, y in get_batches(data, batch_size, seq_length): counter += 1 # One-hot encode our data and make them Torch tensors x = one_hot_encode(x, n_chars) inputs, targets = torch.from_numpy(x), torch.from_numpy(y) if(train_on_gpu): inputs, targets = inputs.cuda(), targets.cuda() # Creating new variables for the hidden state, otherwise # we'd backprop through the entire training history h = tuple([each.data for each in h]) # zero accumulated gradients net.zero_grad() # get the output from the model output, h = net(inputs, h) # calculate the loss and perform backprop loss = criterion(output, targets.view(batch_size*seq_length)) loss.backward() # `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs. nn.utils.clip_grad_norm_(net.parameters(), clip) opt.step() # loss stats if counter % print_every == 0: # Get validation loss val_h = net.init_hidden(batch_size) val_losses = [] net.eval() for x, y in get_batches(val_data, batch_size, seq_length): # One-hot encode our data and make them Torch tensors x = one_hot_encode(x, n_chars) x, y = torch.from_numpy(x), torch.from_numpy(y) # Creating new variables for the hidden state, otherwise # we'd backprop through the entire training history val_h = tuple([each.data for each in val_h]) inputs, targets = x, y if(train_on_gpu): inputs, targets = inputs.cuda(), targets.cuda() output, val_h = net(inputs, val_h) val_loss = criterion(output, targets.view(batch_size*seq_length)) val_losses.append(val_loss.item()) net.train() # reset to train mode after iterationg through validation data print("Epoch: {}/{}...".format(e+1, epochs), "Step: {}...".format(counter), "Loss: {:.4f}...".format(loss.item()), "Val Loss: {:.4f}".format(np.mean(val_losses)))# define and print the net n_hidden=512 n_layers=2 net = CharRNN(chars, n_hidden, n_layers) print(net)batch_size = 128 seq_length = 100 n_epochs = 20 # start smaller if you are just testing initial behavior # train the model train(net, encoded, epochs=n_epochs, batch_size=batch_size, seq_length=seq_length, lr=0.001, print_every=10)4. Tips dalam melakukan Training (referensi)a. Monitoring Validation Loss vs. Training Loss(1) jika training loss lebih kecil dari validation loss maka ini berarti network mengalami overfitting. Solusinya perkecil ukuran network atau naikkan dropout.(2) jika training loss hampir sama dengan validation loss maka ini berarti network mengalami underfitting. Solusinya naikkan ukuran network, bisa saja jumlah layar nya maupun jumlah neuron pada setiap layarnya.b. Perkiraan jumlah parameterDua parameter paling penting yang dapat mengontrol model adalah jumlan hidden dan jumlah layer. Terdapat saran unutk selalu menggunakan jumlah layer (n_layer) sebanyak 2/3. komponen hidden (n_hidden) dapat di atur dari berapa banyak data yang dimiliki.(1) jumlah parameter selalu tercetak pada awal training.(2) jumlah dataset sebanyak 1 MB, kemungkinnan memiliki 1 juta karakter.parameter kedua (jumlah dataset) mungkin menjadi tricky untuk dilakukan pengaturan, contohnya:(1) saya memiliki 100MB dataset, dan saya menggunakan parameter default (sekarang tercetak 150K parameter). Data yang saya miliki secara signifikan lebih besar (100 juta >> 0.15 juta), jadi menduga akan underfitting. Jadi saya pikir untuk menaikkan jumlah hidden komponennya (n_hidden).(2) saya memiliki 10MB data, dan saya jalankan pada 10 juta parameter model, saya agak gugup dan terus memperhatikan validation loss. Jika lebih besar dari trainnig loss, maka saya akan menaikkan sedikit dropout, dan kita lihat apakah membatu validation loss?c. Strategi mendapatkan model terbaik(1) strategi untuk membuat model yang sangat bagus (jika anda tidak masalah dengan waktu komputasi) adalah membuat jaringan sebesar mungkin (sebesar kemampuan anda untuk menunggu waktu komputasinya). dan coba berbagai macan nilai dropout (antara 0.1). Validation loss yang terkecil merupakan model yang terbaik.(2) sangat biasa di dalam Depp Learning, unutk menjalankan sekaligus dibeberapa parameter yang berbeda dalam sekali waku. akhirnya ambil model yang terbaik(3) pemecahan data validasi dan data training. pastikan anda memiliki sejumlah data yang layak pada data validasi, jika tidak kinerja validasi akan noisy atau tidak terlalu informatif
No comments:
Post a Comment